

DATAcracy là dự án tích luỹ và lan toả kiến thức về dữ liệu, bao gồm thường thức cho mọi người và các kiến thức chuyên sâu về dữ liệu. Bắt đầu từ 2020 và trở lại trong 2023 với chuỗi 08 data talks diễn ra vào các thứ bảy cách tuần. Mời bạn theo dõi facebook DATAcracy để đăng ký tham gia.
Dẫn nhập
Trong Talk#4 DATAcracy (DTC) có đưa ra một ví dụ về Club 27 khi chỉ số Tương Quan nói dối, rồi chính bản thân chúng ta lại tự vẽ thêm các “suy diễn” từ định kiến vốn có.
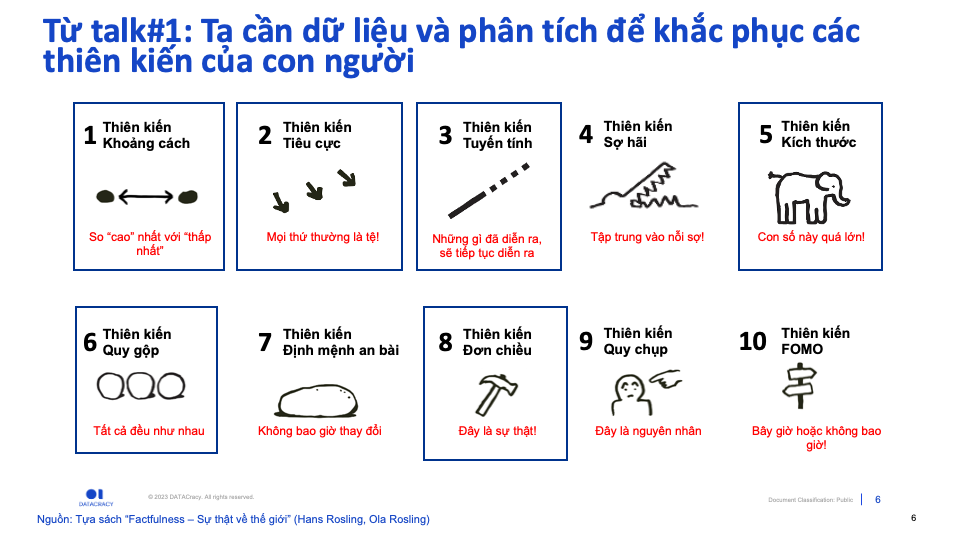
Nhắc lại một chút về nội dung của Talk#1: Factfulness đề cập đến 10 loại thiên kiến mà chúng ta thường gặp phải. Dữ liệu và phân tích được giới thiệu như một cách để khắc phục vấn đề này.
Tuy nhiên, “con số” cũng có lúc “nói dối”. Việc tin tưởng rằng các kết quả được đưa ra từ dữ liệu và mô hình phân tích thì luôn khách quan và đúng đắn (hơn ý kiến con người), dẫn tới xu hướng suy diễn từ định kiến sẵn có để củng cố kết quả từ dữ liệu. Đây là thiên kiến thứ 11, Thiên kế từ dữ liệu và thuật toán (Data & Algorithmic bias)
Talk#5 nói về vì sao lại thiên kiến này xuất hiện và làm cách nào để khắc phục những lời “nói dối” trong lúc làm việc và đọc kết quả từ dữ liệu.
Khi con số nói dối
Hãy bắt đầu bằng việc truy cập vào trang web incidentdatabase.ai - Đây là database cập nhật thường xuyên về các case studies mà dữ liệu và thuật toán có thể mắc phải những “thiên kiến” gây hại cho những cá nhân hay nhóm người nào đó. Website này giúp những ai quan tâm đến dữ liệu và thuật toán hình dung những mặt trái về an toàn, bảo mật, công bằng (AI Fairness) và những thiên kiến có thể tồn tại trong các bài toán phân tích và mô hình từ dữ liệu.

Phải nhớ rằng: Mô hình và kết quả phân tích là dựa trên dữ liệu thuộc về quá khứ. Những gì đã xảy ra có thể “nhuốm màu” những định kiến cố hữu của con người như: Phân biệt đối xử, định kiến về giới tính, giai cấp, màu da.
Khi “đào” và “học” trên các dữ liệu này, mô hình (AI/Machine Learning) sẽ học lại chính các thiên kiến của con người, đưa nó vào quy trình tự động hoá và nhân rộng.

Tình huống phát sinh câu hỏi về AI/Data Fairness và Bias bao gồm các thành phần sau:
- Nhóm yếu thế (Unprivileged): Theo độ tuổi (trẻ em, người già), giới tính (phụ nữ, LGBT), chủng tộc (người dân tộc thiểu số)
- Kết quả có lợi (Favorable Outcome): Được cấp hạn mức tín dụng cao, được đánh giá có mức rủi ro thấp – cho phép tái hoà nhập cộng đồng (crime algorithms), được giới thiệu các dịch vụ tiện ích nhiều hơn, được ưu tiên tiếp cận khám chữa bệnh
- Biến nhạy cảm (Sensitive/Protected attributes): Là các thông tin có tương quan cao, có thể dùng suy đoán và xác định “nhóm yếu thế” thông tin về tuổi, giới tính
Các kết quả có lợi (tiên đoán và gợi ý từ mô hình) không được phân phối “công bằng” giữa nhóm yếu thế và nhóm lợi thế.
Dưới đây là 04 case studies “Khi-con-số-nói-dối” - AI/Data Fairness.
(1) Hạn mức cho vay: Phân biệt giới tính
Hai vợ chồng có cùng mức thu nhập (theo khai báo thuế) và tài sản sở hữu như nhau, nhưng người nam giới lại được cho phép hạn mức tín dụng cao gấp 20 lần so với người vợ.
Hạn mức tín dụng này là kết quả từ mô hình tiên đoán rủi ro và đề xuất hạn mức tín dụng, được huấn luyện trên dữ liệu quá khứ khi các quyết định phê duyệt tín dụng có thể có định kiến với phụ nữ (ví dụ: mặc định phụ nữ sẽ làm nội trợ, có thu nhập thấp và ít ổn định hơn so với nam giới).
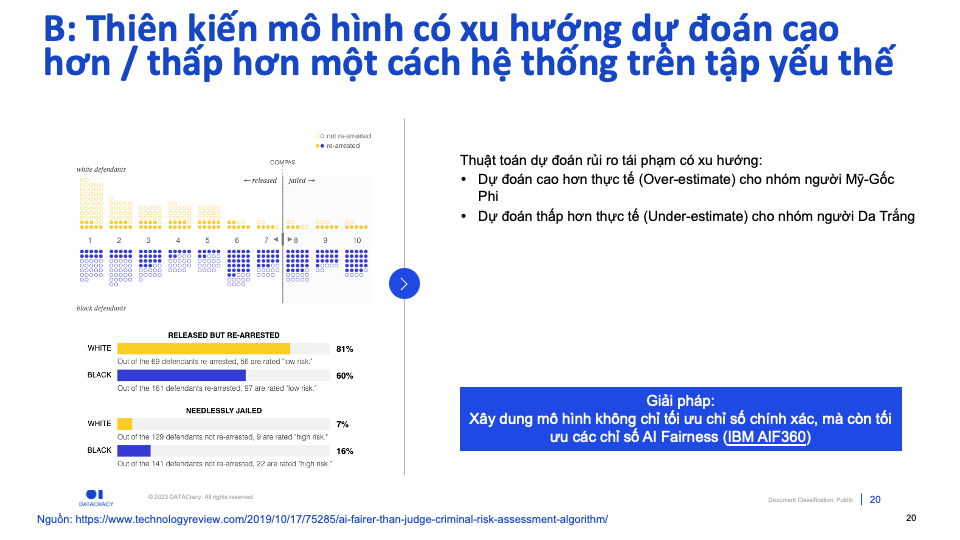
(2) Dự đoán rủi ro tái phạm: Phân biệt màu da
Hình bên dưới là các tù nhân và mức điểm rủi ro được dự đoán bởi mô hình về khả năng tái phạm (điểm càng cao thì rủi ro tái phạm càng cao). Điểm số này là một trong những yếu tố toà án sẽ cân nhắc khi ra quyết định.
Ngoài mức điểm của mỗi tù nhân, thông tin về tiền án tiền sự cũng được cung cấp.

Bạn thấy có gì lạ?
Đọc vào tiền án tiền sự, ta có thể thấy mô hình có xu hướng nghiêm khắc hơn nhiều so với các bị cáo gốc Phi, trong khi lại có cho điểm rủi ro thấp hơn hẳn với các bị cáo da trắng.
(3) Thiết kế an toàn trên ô tô
So với Nam giới, nguy cơ bị thương nặng khi tai nạn ô tô xảy ra ở phụ nữ cao hơn đến 73% (Nguồn: ConsumerReports.com)

Sự “bất công” này xảy ra do các hình nộm dùng cho thực nghiệm kiểm tra va đập tai nạn ô tô trong quá trình thiết kế và sản xuất, được thiết kế theo cơ thể của nam giới.
Vì vậy, các thiết kế an toàn và chống va đập (như túi khí) thiếu các điểm dữ liệu thực nghiệm để “cân nhắc” và điều chỉnh cho phù hợp để đảm bảo an toàn cho nữ giới.
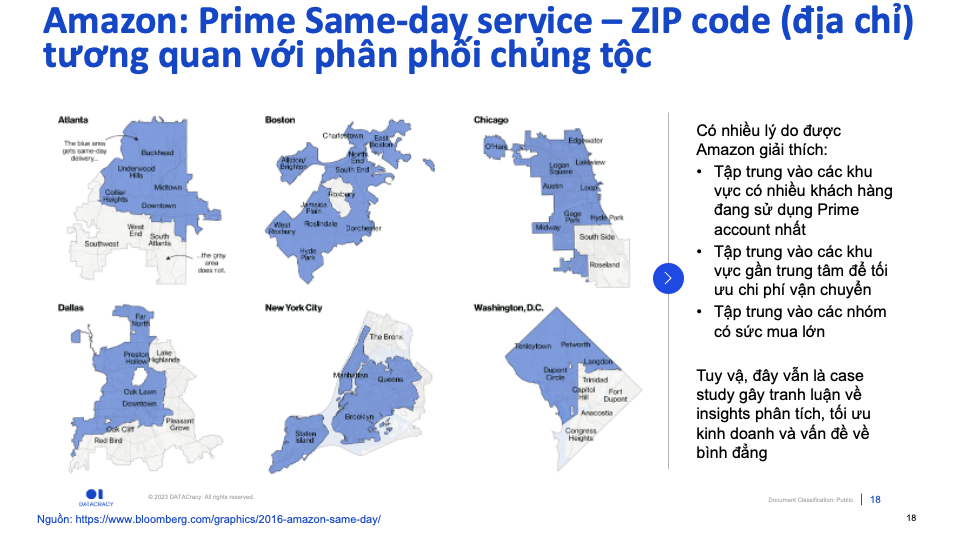
(4) Amazon same-day service
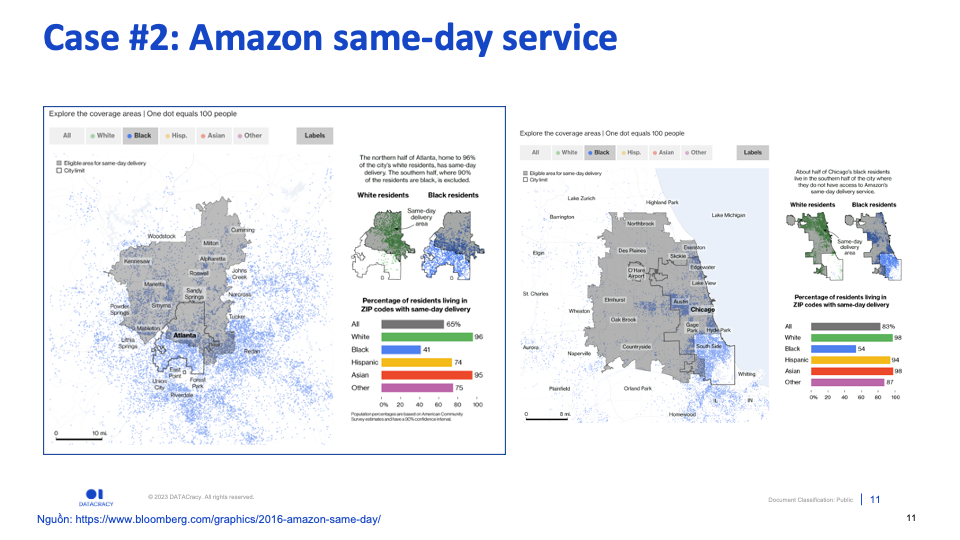
Amazon giới thiệu một tiện ích giao hàng trong ngày (“Same-day service”) cho tập khách hàng đăng ký Prime .
Dù tự hào luôn cùng cấp các sản phẩm chất lượng và giá cả tương đồng cho mọi tầng lớp, giới thích và sắc tốc. Dịch vụ này của Amazon chỉ tập trung vào một số ZIP code, và khi vẽ ra trên bản đồ (Bạn có thể tương tác với dữ liệu tại ĐÂY) các khu vực tập trung cộng đồng “Black” thường không nằm trong vùng phủ sóng của dịch vụ này.
Việc lựa chọn địa bàn là kết quả phân tích về nhiều yếu tố: Tiềm năng khu vực, Tối ưu chi phí vận chuyển, v.v…
Lời nói dối bắt đầu từ đâu
Vì sao các “thiên kiến” trên có thể len lỏi vào mô hình?
Trong Talk#2, DTC đã giới thiệu quy trình chuẩn gồm 6 bước để phân tích dữ liệu.
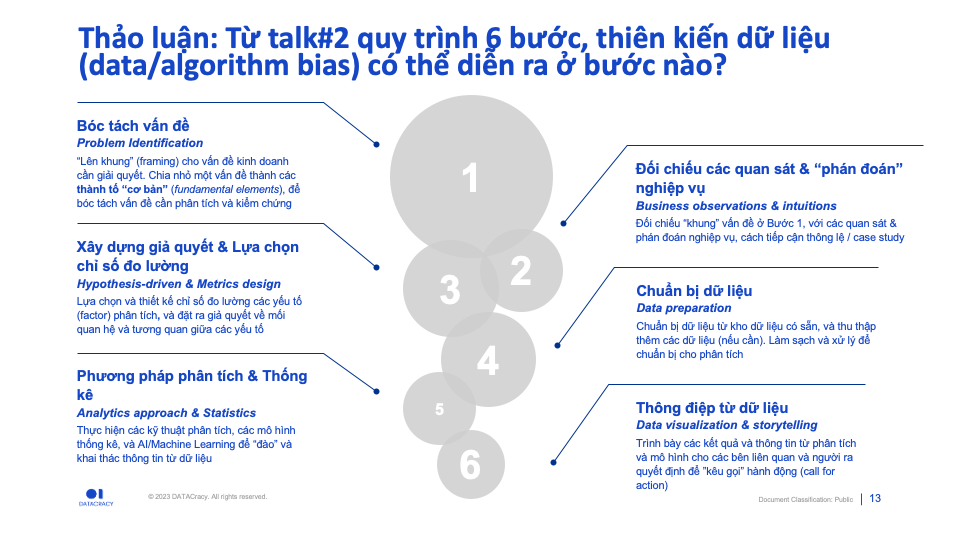
Data Science dưới góc nhìn “đường ống”
Quy trình 6-bước trên được trình bày dưới góc nhìn “đường ống” (pipeline):
- Từ 03 bước đầu tiên của việc phân tích và xây dựng giả thuyết, dữ liệu từ các sự kiện sẽ được tiến hành thu thập và “đường ống dữ liệu” được thiết kế
- Data pipeline sẽ có 3 bước cơ bản:
–Pre-processing: Xử lý, làm sạch, biến đổi dữ liệu–In-processing: Các bước phân tích và mô hình hoá–Post-processing: Xử lý “hậu kỳ”, tinh chỉnh kết quả đầu ra từ phân tích và mô hình - Với thông tin và dự đoán từ Data pipeline, chúng ta tiếp tục phân tích, bóc tách và xây dựng các giả thuyết mới
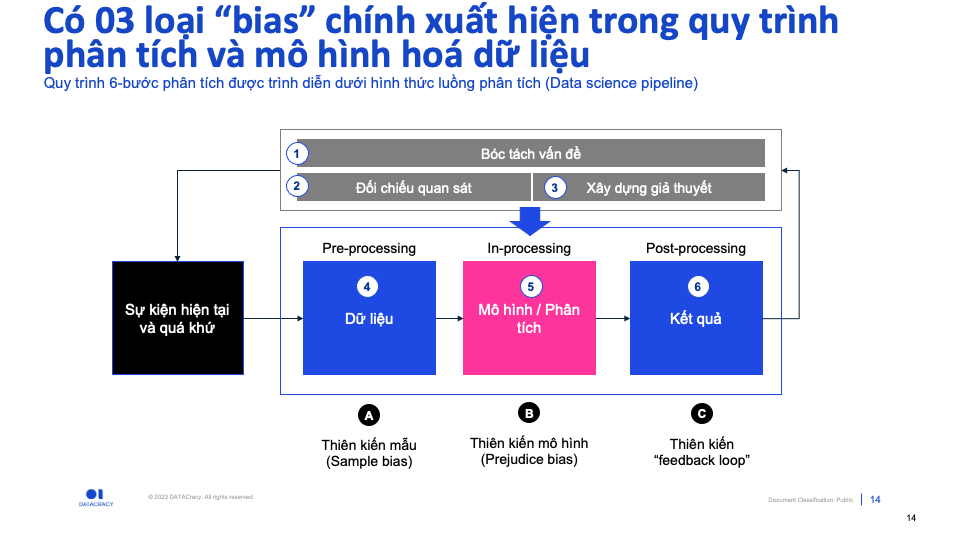
03 loại “bias” chính
Các sai sót và ngộ nhận diễn ra trong 3 bước của quá trình bóc tách vấn đề và xây dựng giả thuyết thường đến từ 10 “bias” của con người. Vì tự ý thức được “con người” thì dễ sai, nên các bước thường được tiến hành cẩn trọng.
Data & Algorithmic bias diễn ra bên trong Data pipeline. Có 03 loại “bias” chính, tương ứng với các bước khác nhau của: Pre-, In-, Post-processing.
- (Pre-processing) (A) Thiên kiến mẫu (
Sample bias): Mẫu dữ liệu sử dụng bị mất đối xứng và không cân bằng quan sát đại diện giữa nhóm “ưu thế” và nhóm “yếu thế”, hoặc chứa các thông tin bao hàm sự thiên lệch sẵn có trong dữ liệu - (In-processing) (B) Thiên kiến định kiến mô hình (
Prejudice bias): Mô hình có xu hướng tiên đoán thiên lệch một cách có hệ thống giữ nhóm “ưu thế” và nhóm “yếu thế”. Ví dụ: Thường xuyên “over-estimate” mức độ rủi ro của tù nhân da màu - (Post-processing) (C) Thiên kiến “feedback loop”: Định nghĩa và diễn dịch “Kết quả” không tuyệt đối và có thiên lệch so với sự thật do “Confirmation bias”. Ví dụ: Đo lường mức độ khoẻ mạnh bằng mức chi tiêu thấp hơn cho chi phí bệnh viện và thuốc thang. “Bias” diễn ra do có những người đau ốm nhưng không có sức chi trả.
Cách khắc phục: Responsible Analytics
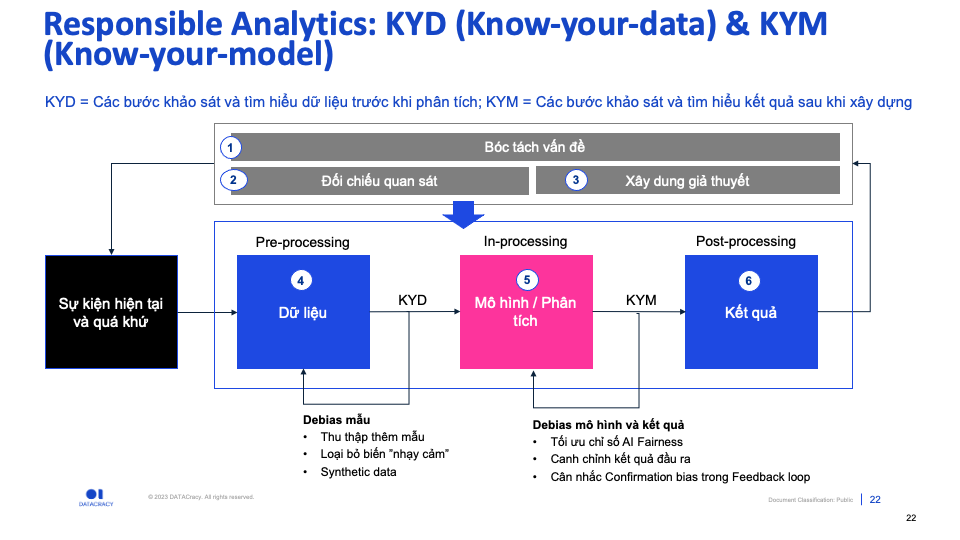
(A) Thiên kiến mẫu: KNOW-YOUR-DATA
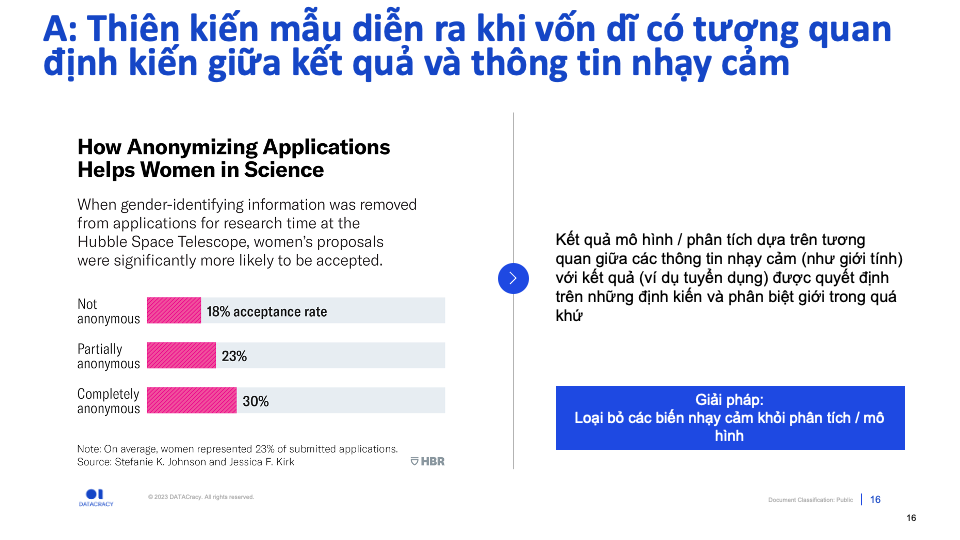
Trong ví dụ thiết kế an toàn trên ô tô, thiên kiến mẫu diễn ra do các quan sát (hình nhân) lệch hẳn về nhóm nam giới, và thiếu các đại diện cho nhóm nữ giới. Giải pháp ở đây là bổ sung thêm các hình nhân theo cấu tạo cơ thể nữ giới và thực hiện thêm các thực nghiệm kiểm chứng trên hình nhân “nữ”.

Cũng trong bước Pre-processing này, một số quốc gia sẽ yêu cầu loại bỏ các Biến “nhạy cảm” (Sensitive attributes) như giới tính, chủng tộc, độ tuổi… hoàn toàn khỏi dữ liệu để hạn chế các thiên lệch.
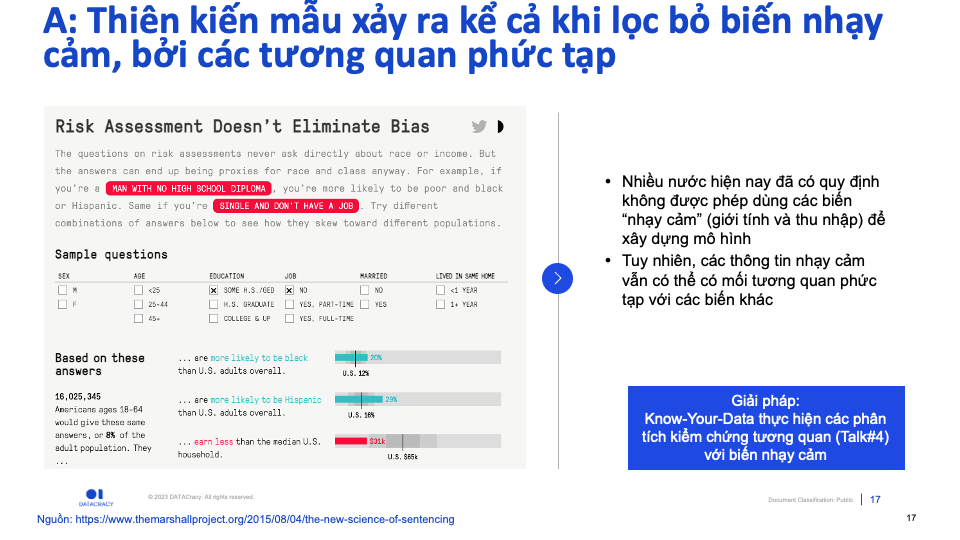
Tuy nhiên, cần lưu ý rằng: Kể cả khi loại bỏ các biến “nhạy cảm”, vẫn còn nhiều biến liên quan không trực tiếp đến các thông tin này. Ví dụ: ZIP code và chủng tộc như trong ví dụ Amazon same-day service.
Trong một số trường hợp, không thể dễ dàng thu thập dữ liệu mới, hoặc lọc các “quy luật” và biến “nhạy cảm”, có thể áp dụng phương pháp nâng cao để tạo ra Dữ liệu “nhân tạo”(Synthetic data), để làm “cân bằng” lại các phân phối giữa nhóm “ưu thế” và “yếu thế”.
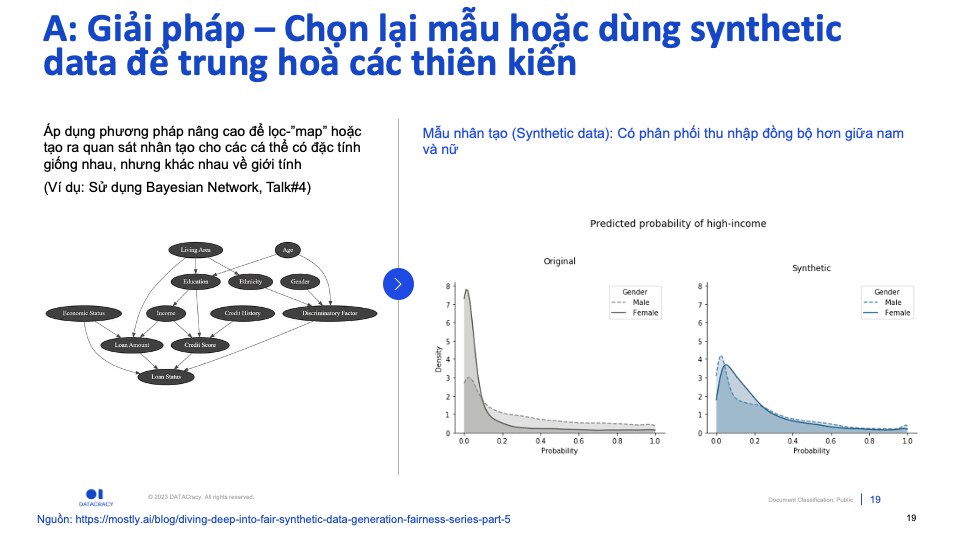
(B) Thiên kiên mô hình: KNOW-YOUR-MODEL
Thiên kiến này có thể phát hiện bằng việc phân tích “hậu kỳ” trên kết quả đầu ra của mô hình, và dùng các phương pháp và chỉ số “Fairness” như một yếu tố khác cần tối ưu, bên cạnh chỉ số về hiệu suất và tính chính xác.
(C) Thiên kiến “Feedback” loop: KNOW-YOUR-OUTPUT

Lab: KYD (Know-Your-Data)
Talk#5 khép lại với lab KNOW-YOUR-DATA để phát hiện các thiên kiến do sự bất cân bằng giữa các nhóm trong dữ liệu hình ảnh.
Bộ dữ liệu: COCC-caption chứa hình ảnh cùng các “caption” và chú thích đi kèm.Trong Biểu đồ nhiệt (heatmap) bên dưới:
- Màu “đỏ” thể hiện tính thiếu đại diện (
under-represented) - Màu “xanh” thể hiện tính đại diện thái quá (
over-represented) cho các nhóm tuổi.
Theo đó, các hoạt động thể chất được “gắn liền” với nhóm tuổi trẻ. Đây có thể dẫn tới các “bias” có thể phát sinh khi xây dựng mô hình trên dữ liệu này.
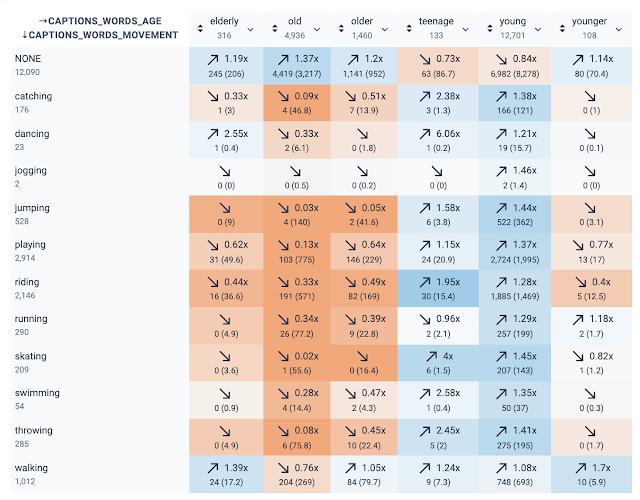
Tương tự, “bias” cũng tồn tại theo nhóm giới tính. Mời bạn khám phá thêm.
Kết
- Thiên kế từ dữ liệu và thuật toán (Data & Algorithmic bias): Mô hình phạm phải chính các thiên kiến của con người trong quá trình đưa ra kết luận
- Data & Algorithmic bias diễn ra bên trong Data pipeline. Có 03 loại “bias” chính, tương ứng với các bước khác nhau của: Pre-, In-, Post-processing. Đó là: Thiên kiến mẫu, thiên kiến mô hình, thiên kiết “feedback” loop
- Phòng bệnh hơn chưa bệnh, có 03 thứ cần “nằm lòng” khi làm việc với dữ liệu để hạn chế các “bias”:
Know-your-data,Know-your-model,Know-your-output.



